
Actually Cloud computing is an umbrella term that is used to indicate a set of services provided over the net. At a broad level, the services can be grouped under the following head
a) IAAS - Infrastructure as a Service
b) PAAS - Platform as a Service
c) SAAS - Software as a Service.
There are other groupings like DAAS for Data as a Service, MAAS, Monitoring as a Service, etc. But the three mentioned above cover the significant chunk of the offerings currently available on the Cloud.
In this blog, I do not intend to go about defining these all over again. One can just google on these titles and should be able to get detailed information on each of these. What I intend to provide is few images which I picked over the net ( I have referenced the source for each of the images) that provide a quick snapshot on what each of the services offer and its value preposition.
So what do these mean?

The grouping is based on the class of services provided and the intended audience.
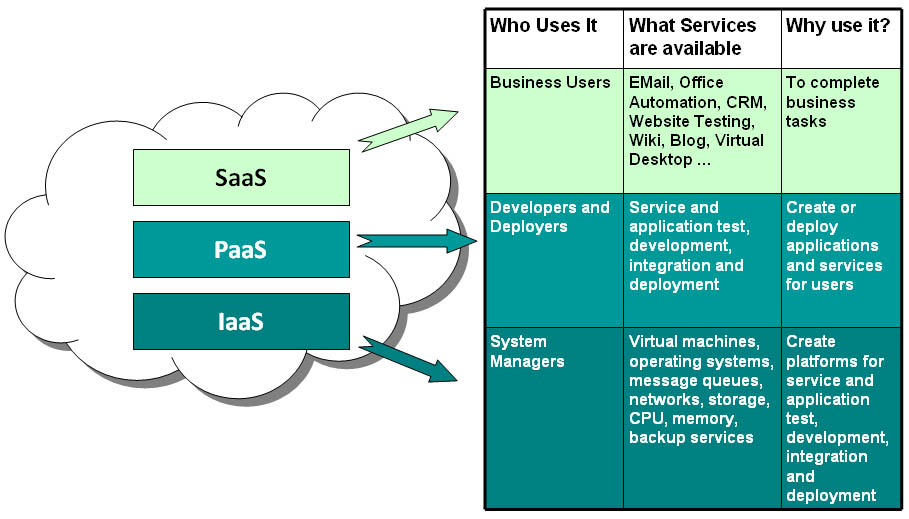
source: info.apps.gov
Another way to look at it is based on what the intended objective is.

source: silverlighthack.com
If you want look at it as a stack, this is how it would look

source: saasblogs.com
If we are to expand each of the layers and see what you get, it would look like this.

Source: Katescomment.com
And finally, you are expected to manage the following with each of the cloud layers

Source: cioresearchcenter.com
Comments
Post a Comment